Journal Review | Learning to Paint With Model-based Deep Reinforcement Learning - (2) 본문
Journal Review | Learning to Paint With Model-based Deep Reinforcement Learning - (2)
생름 2023. 6. 16. 00:38Huang, Zhewei, Wen Heng, and Shuchang Zhou. 2019. "Learning to Paint With Model- Based Deep Reinforcement Learning." In Proceedings of the IEEE International Conference on Computer Vision, pp-8709–8718. PDF
ICCV 2019 Open Access Repository
Zhewei Huang, Wen Heng, Shuchang Zhou; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 8709-8718 We show how to teach machines to paint like human painters, who can use a small number of strokes to create fantastic
openaccess.thecvf.com
1. How does Learning to Paint with Model-based Deep Reinforcement Learning(DRL) actually work?
I planned to skim the LearningToPaint source codes on GitHub for my practical understanding of Model-based Deep Reinforcement Learning, hoping to find a link from the algorithms diagrams on the paper. It was my first time looking through these training parameters of machine learning, so I would like to narrow it down and discuss a few interests of mine in the scripts and desciption on paper.
2-1. DDPG of model-free and model-based. How different?
In the paper, the author compared the model-based DDPG and the model-free DDPG. (DDPG is a branch of Reinforcement Learning.) The author’s explanation nearly aligned with the comparison of DRLs(#2-3) I made below. The model-based DDPG is modeling the environment through a neural renderer which helps an agent efficiently, while the original, model-free DDPG observes the environment and rewards from the environment implicitly. Besides, model-free DDPG requires high dimensional action space for every loop. From these circumstances, the model-based DDPG brings better rewards in a short time. Its reward is accessed by the change rate between the loss A of the target image and canvas(in step N) and the loss B of the target image and canvas(in step N+1), and each loss(L2) made from the model-based DDPG at once was 100 times smaller than from the model-free DDPG. Thus, the model-based DDPG could reach the target image way faster as its loss converges to zero.
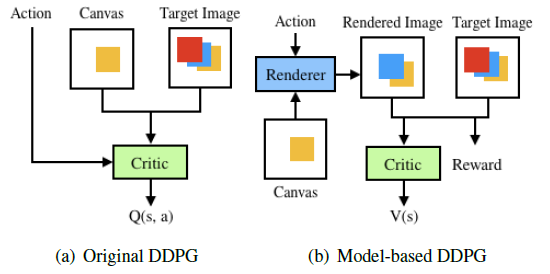
2-2. Deep Reinforcement Learning(DRL) of model-free and model-based. How different are they if both have a neural renderer?
On GitHub, the source codes the author shared have two independent sessions for training, (1) baseline DRL with model free and (2) baseline DRL, the amended final version. The author briefly mentioned on Reddit that it was surprising to train a neural renderer with a simpler setting after a few years of struggling with model-free RL. Thus it is no wonder at first I assumed the algorithms with model-free on GitHub might be without neural networks as model-free DDPG is. But the model-free version of DRL, as the name ‘Deep’ Reinforcement Learning refers to, also uses neural network models. By comparing the two sessions on GitHub, I learned that even model-free DRL could bring a neural network model and model-free is not the opposite of a neural network model. Model-free DRL and neural renderers are compatible.
2-3. Model-free DRL VS Model-based DRL
I searched how different the model-based DRL and the model-free DRL were because both of them were seemingly using a neural networks model on GitHub.
- Data collection
- Model-free DRL with a neural network model: An agent collects data by interacting with the actual environment. No additional environment model. Used for the less complicated case that requires simple calculation and easy demonstration.
- Model-based DRL with a neural network model: An agent collects data inside the environment model. This model will help the agent to predict the next states and rewards. Its prediction makes the process more efficient and allows planning and inferring.
- Learning method
- Model-free DRL with a neural networks model: Training neural networks with data.
- Model-based DRL with a neural networks model: Training neural networks with environment data to minimize the loss of state/reward prediction.(Probably I need to figure out how environment operates its training in ML)
2-4. The paper and the scripts: What is the model-free version of independent scripts the author intends?
The author describes whether the use of a neural renderer is the main distinction between model-based DDPG and model-free DDPG. However, both of the scripts, model-free and general DRL have neural renderers. Besides, I described in #3-1, the simulation part that the testing outputs from these two DRL would exactly the same, and the training outputs were unable to see the results. Despite the fact the two independent scripts are likely the model-free and the model-based DRL both with neural network models, I was confused because the same output is shown in testing session of the two different baselines. Would my computer deal with the training session to tell the difference of the model-free baselines type and to understand the authors' purpose? I have no choice but to look through the scripts for understanding the use of the model-free version.
3-1. Testing Simulation and Comparison
I attempted the testing on the collab page using my profile image. In combination with GitHub, it was easy to follow the algorithms sequence described in the paper. As I found its DRL codes have two types, the model-free and the model-based on Github, I tried both for analyzing the result and the process rate. My lack of knowledge allowed me to hypothesize what model-free means only implicitly. That was, through comparing the loss L2 (the distance between step 2 canvas and target image) with the one from the model-based version. As I mentioned above, in the paper, the model-based would produce 100 times smaller L2 than model-free DDPG algorithms while training. Will the difference appear even in the testing? The result was, maybe it is unlike in the training, both L2 values were the same. It means the processing time between the two baselines was shown no different.
Below shown are the L2 outputs of each step in both algorithms with a neural renderer.
canvas step 0, L2Loss = 0.03215230256319046
canvas step 39, L2Loss = 0.004075238481163979
divided canvas step 0, L2Loss = 0.0018783402629196644
divided canvas step 39, L2Loss = 0.0003712972393259406
*divided canvas: default value = 4, here 5, divide the target image to get a better resolution. The less divided number, the bigger L2Loss and the more steps to end.

As the step progresses, the size of the strokes becomes smaller. It is similar to how a real painter draws as the one would outline light and shade first and gradually depict the smaller detail. Unlike humans, the machine is able to capture and add small details all in one phase when the step is close to the end, which seems artificial and reminds me of a similar technique when increasing the resolution of real pictures. However, I agree with the authors’ expectation that LearningToPaint would help oil painting beginners to draw more accurately.
3-2. Training Simulation, a failure
On the other hand, this collab page also represented the training algorithms. I concluded that the baseline of model-free DRL shall exist for the training session. Unlike the testing session, it was hard to grasp its concept and the purpose of sharing. Is it even possible to conduct machine learning on my computer with GPU 3060? Will my computer be shut down? I can’t estimate until I confront it, so I downloaded 1.5GB of the CelebA zip file and attached the unzipped file to the collab directory. CelebA is a dataset of celebrity faces’ images from Large-scale CelebFaces Attributes (CelebA) Dataset in 2015. The authors used four types of datasets including CelebA to conduct their research. If the amount of meaningful data was ready, I bet the rest of the work was a piece of cake for them.


Unzipping 0.2 million images took 1.5 hours on my laptop. I attempted to put them in the right directory of the Collaboratory but it was impossible to proceed further. This is what machine learning requires, and I probably invest more money in my machine for its education.
I admit that I was little ambitious to figure it out how training works via executing LearningToPaint algorithms, but probably I have to find better sources on Youtube and learn the practical knowledge of training of machine implicitly. The testing process for output with new input after machine learning complete its new script and the training process of machine learning are independent. Some say training process is nothing but collecting data and it is more important to propose how to test it in the practical world, for example, like Autodesk Revit in combination with chat GPT.
Learning the cases of training would allow me more flexible thinking on ML. So far I have only one way to find the answer, which is to compare the two baselines DRL scripts with only a small difference. Thus, I would like to dig into training session while glancing the source codes by next week.



